
英伟达的Blackwell架构在实现大批量生产方面遇到了重大问题。这一挫折已影响到该公司2024 年第三季度/第四季度以及明年上半年的生产目标。
而英伟达的 Hopper 架构在使用寿命和出货量上都得到了延长,在最大程度上弥补Blackwell的延迟。技术挑战也促使英伟达不辞辛苦地创建不在计划内的全新系统,对数十家上下游供应商产生巨大影响。
今天我们将介绍英伟达面对的技术挑战、修订后的时间表,并详细介绍包括新的 MGX GB200A Ultra NVL36在内的新系统。

资料来源:SemiAnalysis Estimates、Nvidia
01.
Blackwell遇困的核心问题
英伟达 Blackwell 系列中技术最先进的芯片是 GB200,在系统级别的多个方面都做出了激进的技术选择。尽管多数数据中心部署的标准是每个机架 ~12kW 至 ~20kW,但 72 GPU 机架的功率密度为每机架约125kW。
这是以前从未实现过的计算和功率密度,考虑到所需的系统级复杂性,这条路已被证明具有挑战性。首先,这里面出现了许多与供电、过热、水冷供应链路、快速断开导致的漏水以及各种电路板复杂性挑战相关的问题。虽然这些让部分供应商和设计师手忙脚乱,但都是小问题,并不是英伟达产量减少或重大路线图返工的原因。
影响出货的核心问题与英伟达的Blackwell架构设计直接相关。尤其,台积电的封装问题和英伟达的设计,导致Blackwell的供应受到限制。
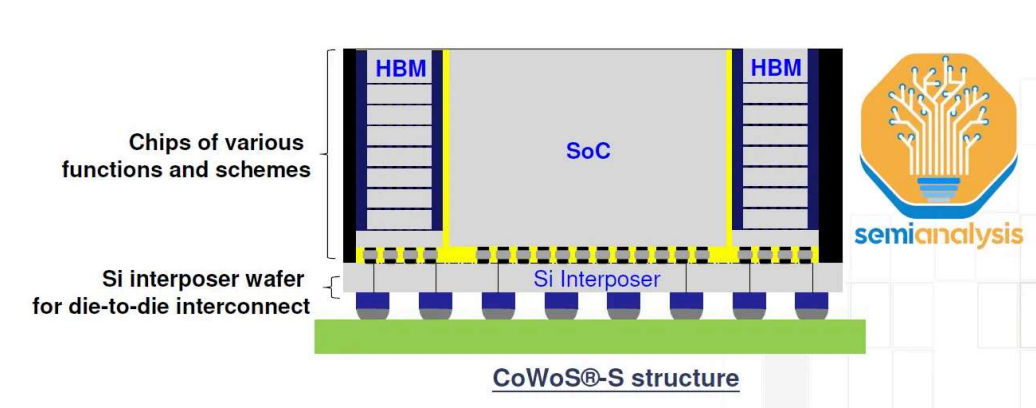
Blackwell,第一个大批量采用台积电CoWoS-L封装技术。
 来源:
台积电
来源:
台积电
回顾一下,CoWoS-L使用带有本地硅互连(LSI)的RDL中介层,并在中介层中嵌入桥接芯片,以桥接封装上各种计算和内存之间的通信。与此相比,CoWoS-S在表面上简单得多,是一块巨大的硅片。
CoWoS-L 是 CoWoS-S 的继任者。随着未来的 AI 加速器容纳更多的逻辑、内存和 IO,CoWoS-S 封装尺寸的增长和性能面临挑战。台积电已经利用AMD的MI300将CoWoS-S的中间层缩放到3.5倍光罩大小。但是,这已然达到极限。这里面存在很多门控因素,关键因素在于硅易碎——中介层越大,处理相当薄的硅片就越困难。随着越来越多的光刻光罩拼接,这些大型硅中介层的成本也越来越高。
来源:台积电
有机中介层可以解决这个问题,它们不像硅那样脆,但是缺乏硅的电气性能,因此不能为更强大的加速器提供足够的I/O。此时,硅桥(无源或有源)可用来补充信号密度以进行补偿。此外,这些桥接板的性能/复杂性可能高于大型硅中介层。
CoWoS-L是一项复杂得多的技术,但它代表着未来。英伟达和台积电的目标是非常激进地将芯片产量提高到每季度超过100万块。因此,出现了各种各样的问题。
其中一个问题与在中介层和有机中介层中嵌入多个精细凸块间距桥有关 ,这会导致硅芯片、桥、有机中介层和衬底之间的热膨胀系数 (CTE) 不匹配,从而导致翘曲。
 来源:Resonac
来源:Resonac
桥接芯片的放置需要非常高的精度,特别是当涉及到两个主要计算芯片之间的桥接时。这些桥接对于支持10 TB/s芯片-芯片互连至关重要。有传言说,一个主要的设计问题与桥接芯片有关。这些桥接需要重新设计。还有传言称,Blackwell 芯片顶部的几个全局布线金属层和bump需要重新设计。这是延迟数月的主要原因。
此外, 还存在台积电总体上没有足够的CoWoS-L产能的问题 。台积电在过去几年中建立了大量的 CoWoS-S 产能,英伟达贡献了大部分份额。现在,随着英伟达迅速将需求转移到CoWoS-L,台积电正在为CoWoS-L建造一个新的晶圆厂——AP6,并在AP3转换现有的CoWoS-S产能。台积电需要转换旧的 CoWoS-S 产能,否则它将得不到充分利用,并且 CoWoS-L 的爬坡速度也将会更慢。产能转换过程本就使CoWoS-L的生产充满波折。
雪上加霜之下,很明显,台积电将无法像英伟达所希望的那样提供足够的Blackwell芯片。因此,英伟达几乎完全专注于 GB200 NVL 36x2 和 NVL72 机架级系统。除了一些初始较低产量外,带有 B100 和 B200 的 HGX 规格现在实际上已被取消。
 资料来源:
SemiAnalysis Estimates、Nvidia
资料来源:
SemiAnalysis Estimates、Nvidia
02.
英伟达的替代方案
为了满足需求,英伟达现在将推出基于 B102A 芯片的名为 B200A 的 Blackwell GPU。有趣的是,这款B102芯片也将用于中国版的Blackwell,名为B20。
B102 是一款带有 4 个 HBM 堆栈的单片计算芯片。重要的是,这使得芯片可以封装在CoWoS-S上,而不是CoWoS-L上,甚至是英伟达的其他2.5D封装供应商,如Amkor、ASE SPIL和三星。原有的Blackwell 芯片有大量专用于 C2C I/O 的海岸线区域,这在单片 SOC 中是不必要的。
B200A将用于满足对低端和中端AI系统的需求,并将取代 HGX 8-GPU 规格的 B100 和 B200 芯片。它将采用 700W 和 1000W HGX 规格,配备高达 144GB 的 HBM3E 和高达 4 TB/s 的内存带宽。值得注意的是,这比 H200 的内存带宽要小。
谈到 Blackwell Ultra——Blackwell 的中期增强版,这款标准的 CoWoS-L Blackwell Ultra 将被称为 B210 或 B200 Ultra。Blackwell Ultra 包含高达 288GB 的 12 Hi HBM3E 内存刷新和高达 50% 的 FLOPS 性能增强。
B200A也将有一个Ultra版本。值得注意的是,它不会进行内存升级,尽管芯片可能会重新设计以提高 FLOPS。B200A Ultra 还引入了全新的 MGX NVL 36 规格。B200A Ultra 也将采用 HGX 配置,就像原来的 B200A 一样。
 资料来源:
SemiAnalysis Estimates、Nvidia
资料来源:
SemiAnalysis Estimates、Nvidia
对于超大规模云服务市场,我们认为 GB200 NVL72 / 36x2 将保持强吸引力,因为它在推理过程中对超过 2 万亿参数的模型具有最高的性能/TCO。话虽如此,如果超大规模云服务客户无法获得他们想要的尽可能多的 GB200 NVL72 / 36x2 ,他们可能仍然需要购买 MGX GB200A NVL2。此外,在功率密度较低或不允许/无法获得水进行液体冷却改造的数据中心,MGX NVL36 看起来更具吸引力。
HGX Blackwell服务器是用于出租给外部客户的最小计算单位,因此仍将被超大规模云服务商购买,但它的购买量将比以前少得多。对于小型型号,HGX 仍然拥有最佳的性能/TCO,这些机型不需要大量内存,并且可以适应 NVL8 的单个内存一致性域。
HGX Blackwell 的性能/TCO 也在使用少于 5,000 块GPU 进行训练时大放异彩。话虽如此,MGX NVL36 是许多下一代模型的最佳选择,并且通常具有更灵活的基础设施,因此在许多情况下它是最佳选择。
对于neocloud市场,我们认为大多数客户不会购买GB200 NVL72 / 36x2,因为寻找支持液体冷却或高功率密度的主机托管提供商具有很高的复杂性。此外,对于有限的 GB200 NVL72 / 36x2,大多数 neocloud 的排名通常比超大规模云服务企业更加靠后。
我们认为,像Coreweave这样的最大的neocloud,既自建或改造数据中心,又拥有大型客户,他们会选择GB200 NVL72 / 36x2。对于neocloud市场的其余玩家,大多数人会选择HGX Blackwell服务器和MGX NVL36,因为它们可以仅使用风冷和较低功率密度的机架进行部署。目前,大多数neocloud部署都是针对Hopper的,功率密度为20kW/机架。我们认为,neoclouds 有可能部署 MGX GB200 NVL36,因为这只需要 40kW/机架的空气冷却。
通过使用冷通道封闭系统并跳过数据中心的行列,每个机架 40kW 的部署不会太难。在 neocloud 规模上,neocloud 运营商和 neoclouds 的客户并不真正倾向于考虑其特定工作负载的TCO 性能,相反,他们只是试图采购目前最热门的东西。例如,大多数(如果不是全部)neocloud 客户不使用 FP8 训练,而是选择 bfloat16 训练。A100 80GB 为在 bfloat16 上训练的小型 LLM 提供了更好的TCO 性能。
由于 Meta 的 LLAMA 模型正在推动许多企业和 Neoclouds 的基础设施选择,因此最相关的部署单元是能够适应 Meta 的模型。LLAMA 3 405B 不适合单个 H100 节点,但勉强适合 H200(该模型可以量化,但质量损失很大)。由于 405B 已经处于 H200 HGX 服务器的边缘,下一代 MoE LLAMA 4 肯定不适合 Blackwell HGX 的单个节点,从而极大地影响每 TCO 的性能。
因此,对于推动初创企业和企业部署的最有用的开源模型的微调和推理,单个 HGX 服务器的性能/TCO 会更差。我们对 MGX B200A Ultra NVL36 的估计价格表明 HGX B200A 不太可能畅销。英伟达有多种强大的动机来稍微降低利润率以推动 MGX,因为他们用自己的网络更高的附加率来弥补这一点。
编译自Nvidia's Blackwell Reworked - Shipment Delays & GB200A Reworked Platforms (semianalysis.com)











 沪公网安备31010702008139
沪公网安备31010702008139